去中心化的算法
强一致性、去中心化、高可用的分布式算法:POW、POS、Paxos和raft。状态机复制的共识算法
- 一般只用于配置文件、核心配置和作为强一致的锁使用,不会保存所有数据。
- 拜占庭将军问题:n(人数)>3m(叛徒数)
- 拜占庭帝国派出了几只军队进攻一个城堡,如果这些带队的将军中有叛徒,在只能靠信使通讯的情况下,如何能够保证忠诚的将军同时、准确的行动?
- 这个问题本质是说:
- 在分布式计算机网络中,如果存在故障和恶意节点,是否能够保持正常节点的网络一致性问题。
- 在近40年的时间里,人们提出了许多方案解决这一问题,称为拜占庭容错法。
- 例如兰波特自己提出了口头协议、书面协议法,后来有人提出了实用拜占庭容错PBFT算法,在2008年,中本聪发明比特币后,人们又设想了通过区块链的方法解决这一问题。现在,由于互联网的发展,拜占庭将军问题已经成为一个重要课题,许多的新思路和新算法也在不停的出现。
- 工作量证明POW:增加叛徒的成本
- 权益证明POS、DPOS 代理权益证明、POA 授权证明、PBFT 拜占庭共识算法
- 一致性:CAP Theorem,对于一个分布式系统,不能同时满足以下三点。
- 一致性 Consistency
- 可用性 Availability
- 分区容错性 Partition Tolerance:如有5个节点,中国区三个,美国区两个,他们相互连接。此时海底电缆断掉,中国区三个可以相互连接,美国两个可以连接,就形成了分区,如何在分区之间的一致性和可用性中做取舍。
- 保证一致性,则让一边的服务不可用。若保证可用,则两边的节点会不一致。
- 一致性模型现在一般有:
- 弱一致性:最终一致性。一般用于DNS、Gossip(Cassandra的通信协议)、DynamoDB
- 强一致性:同步,Paxos、Raft(multi-paxos)、ZAB(multi-paxos)
- 强一致性算法:
- 主从同步:master接受写 -> master复制日志到slave -> master等待,直到所有从库返回。这种方式可用性会很差,只要任何一个节点阻塞,整个系统将发生阻塞。引出了多数派方案。
- 多数派:读和写都保证有大于N/2个节点一致。处理并发时,无法保证系统正确性,顺序非常重要。引出了leader方案--paxos。
- 顺序的重要性,如同时有两个操作,set0和inc5(增加5)。日志的顺序:
- 先set0再inc5
- 先inc5再set0
- 得到的结果是不一致的。
- Paxos方案:
-
Paxos 强一致算法
-
基础
- 角色:
- Client:产生议题者,发起新的请求。系统外部角色,请求发起者,类似于民众。
- Proposer:提议者,提出议案(同时存在一个或者多个,他们各自发出提案)。接受client请求,向集群提出提议(propose)。并在冲突发生时,起到冲突调节的作用。类似于议员,替民众提出提案。
- Acceptor(Voter):接受者,收到议案后选择是否接受。提议投票和接收者,只有在形成法定人数(Quorum,一般即为majority多数派)时,提议才会最终被接受。类似于国会,人大。
- Learner:最终决策学习者,只学习正确的决议。提议接受者,backup,备份,对集群一致性没什么影响。类似于记录员。
-
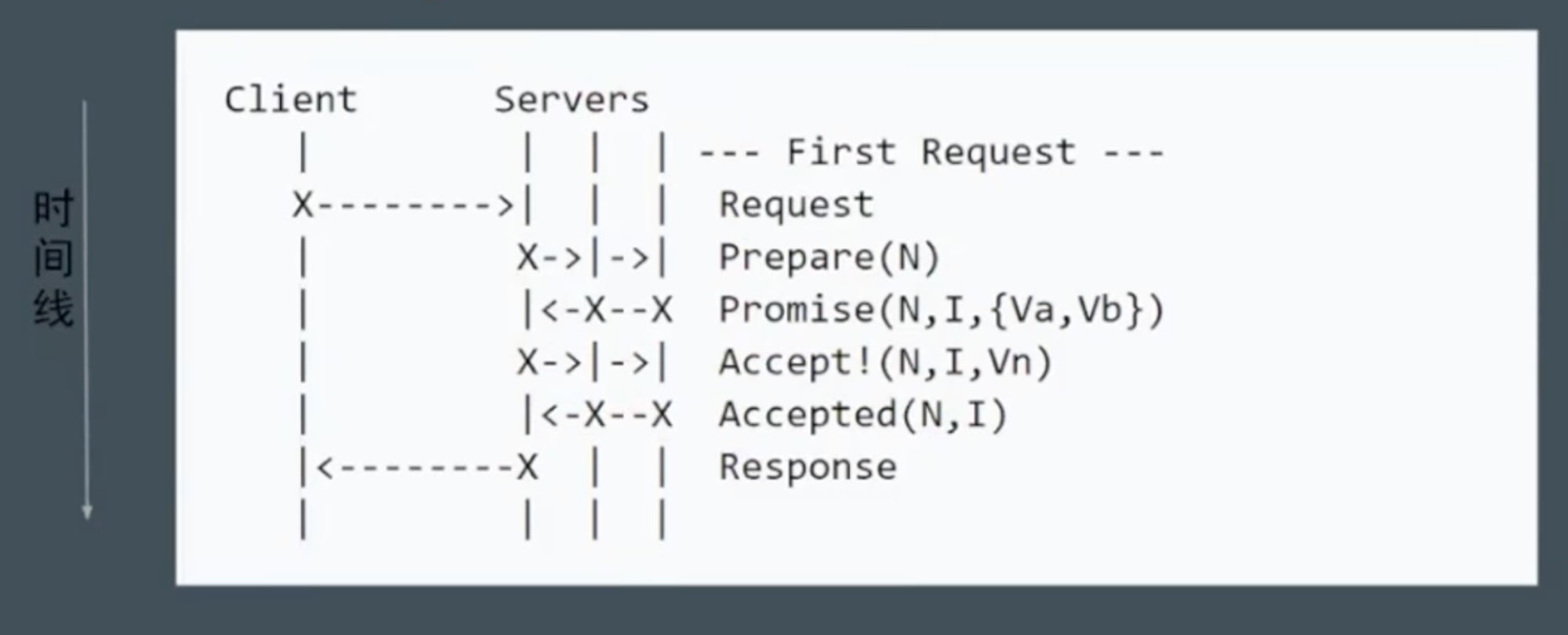
Basic Paxos:效率低
-
步骤和阶段
-
阶段 1a:Prepare 准备
-
proposer提出一个提案,编号为N,此N大于这个proposer之前提出提案编号。请求acceptors的quorum接受。
-
阶段 1b:Promise 承诺
-
如果N大于此acceptor之前接受的任何提案编号则接受,否则拒绝。
-
阶段 2a:Accept 接受
-
如果达到了多数派、proposer会发出accept请求,此请求包含提案编号N,以及此提案的内容
-
阶段 2b:Accepted 已接受
-
如果此acceptor在此期间没有收到任何编号大于N的提案,则接受此提案内容,否则忽略
-
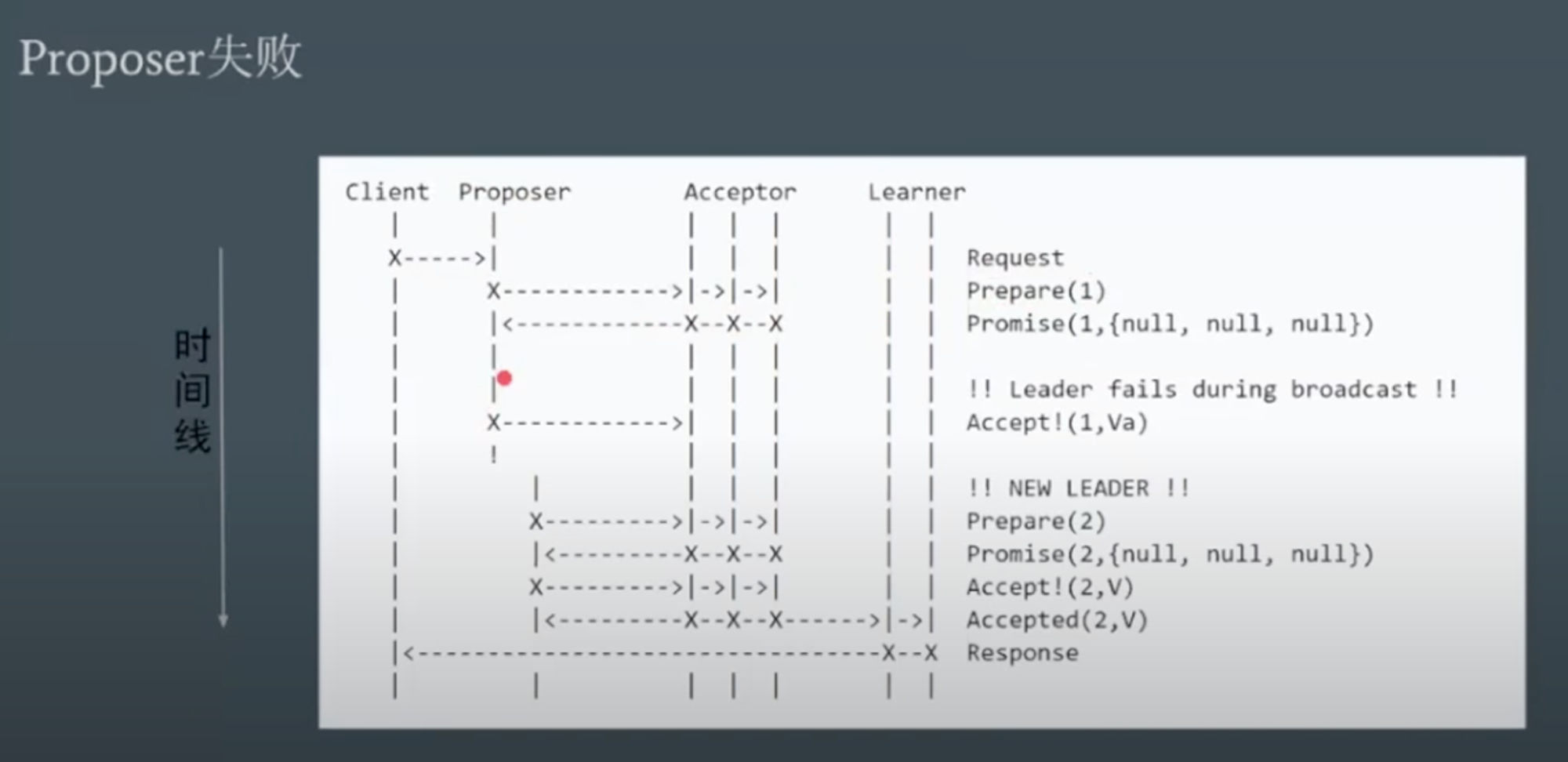
部分节点失败,但达到了Quoroms 法定人数认可

-
潜在问题
-
-
Multi Paxos:加入了Leader:唯一的Proposer,所有的请求都需要经过此Leader
-
将每一轮投票的流程给汇聚到一次Leader选举,选完,之后就不需要再投票了。(多个proposer汇聚成了一个leader。)直到重新选举。
-
-
-
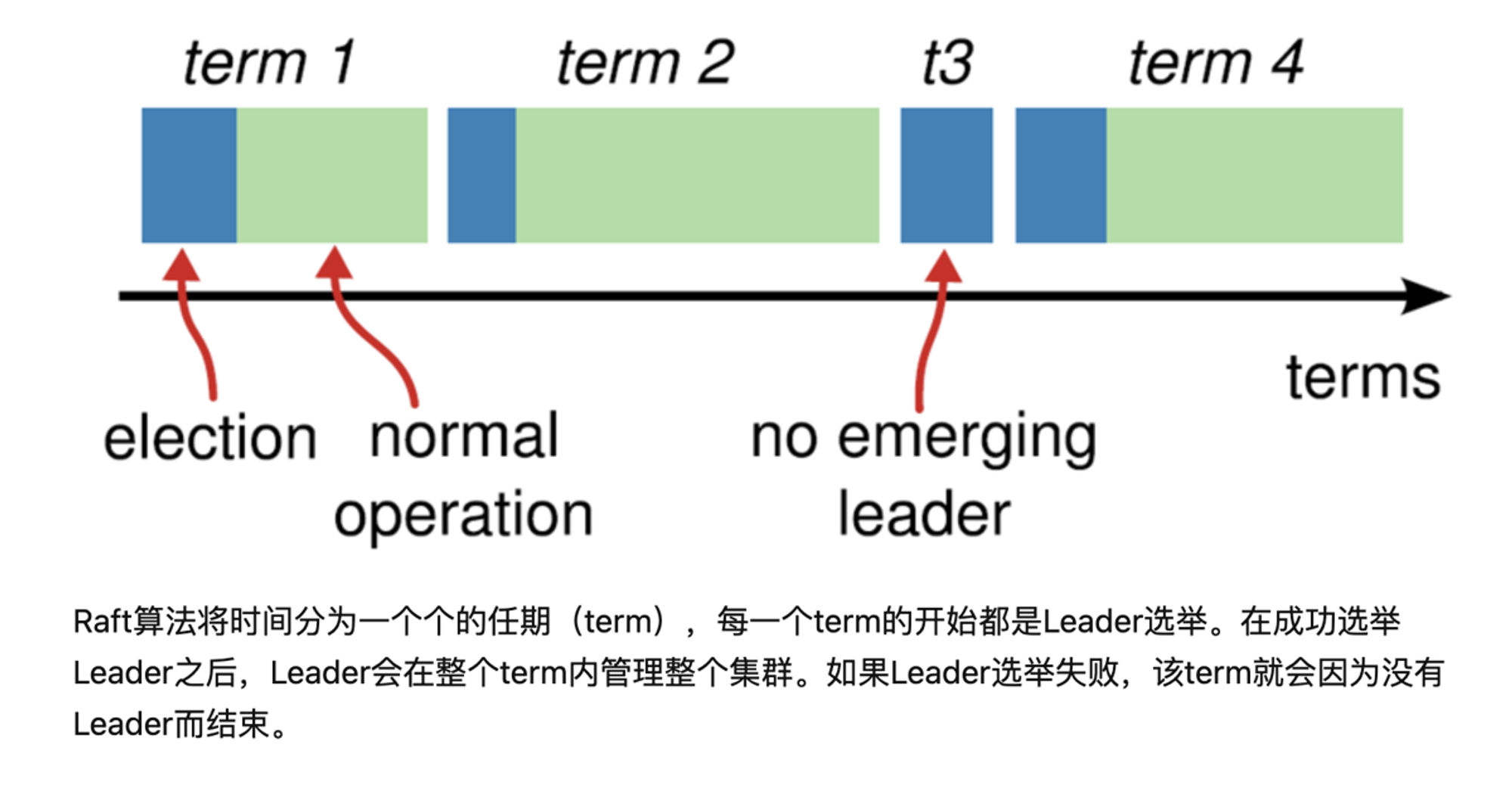
** raft 共识算法:是一个达成分布式强一致性的协议。状态复制机
-
基础知识
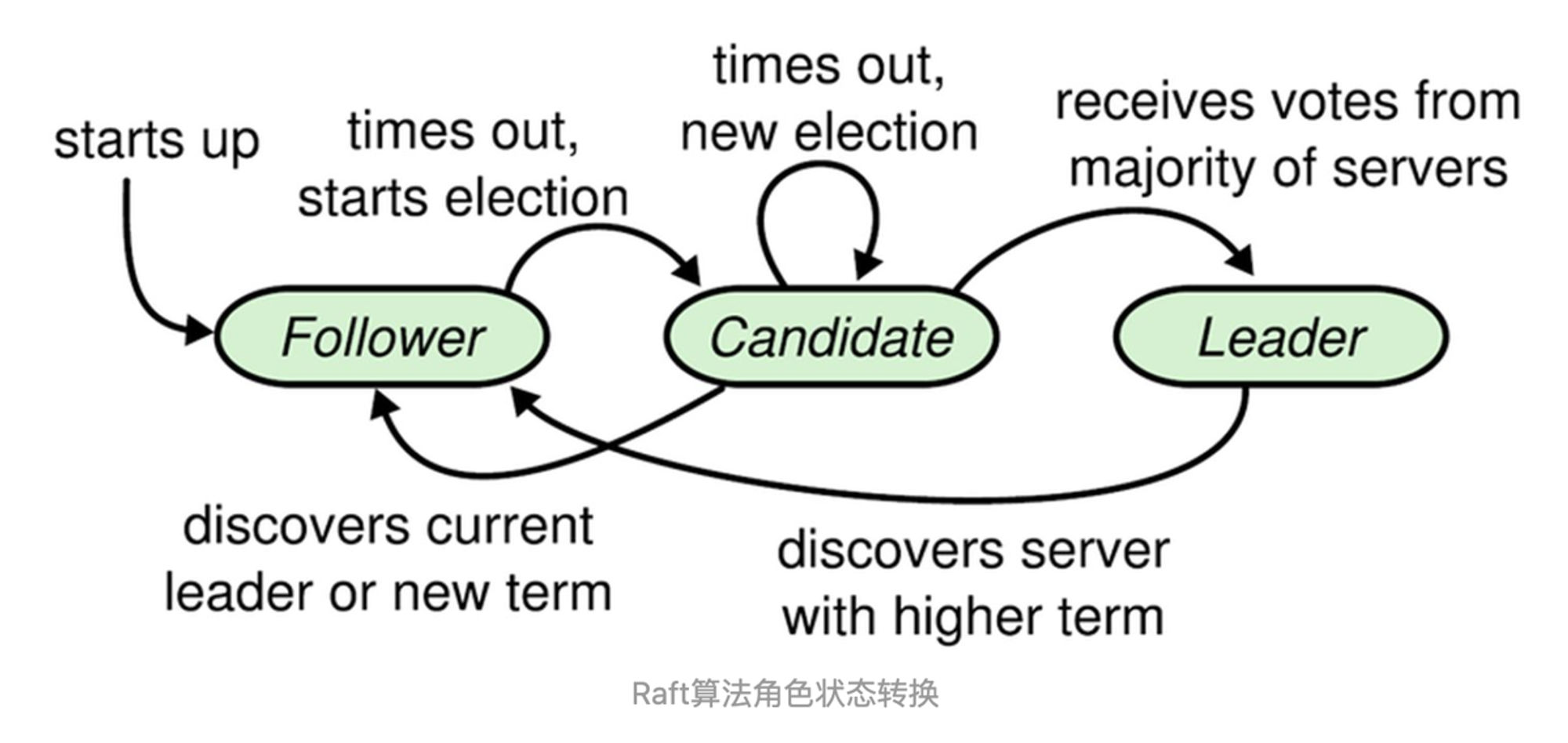
- 角色分为:
- 领导者(Leader):接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。无论节点有多少,leader只能有一个
- 跟从者(Follower):接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
- 候选人(Candidate):Leader选举过程中的临时角色。可以理解为是一种临时的状态。
Open: Pasted image 20240813153601.png
- Raft要求系统在任意时刻最多只有一个Leader,正常工作期间只有Leader和Followers。
Open: Pasted image 20240813153619.png
-
Follower只响应其他服务器的请求。如果Follower超时没有收到Leader的心跳💓消息,它会成为一个Candidate并且开始一次Leader选举。收到大多数服务器投票(自己也可以投票)的Candidate会成为新的Leader。Leader在宕机之前会一直保持Leader的状态。
-
分解成三个子问题:---
-
Leader选举(Leader election)
-
确认leader的过程:------
-
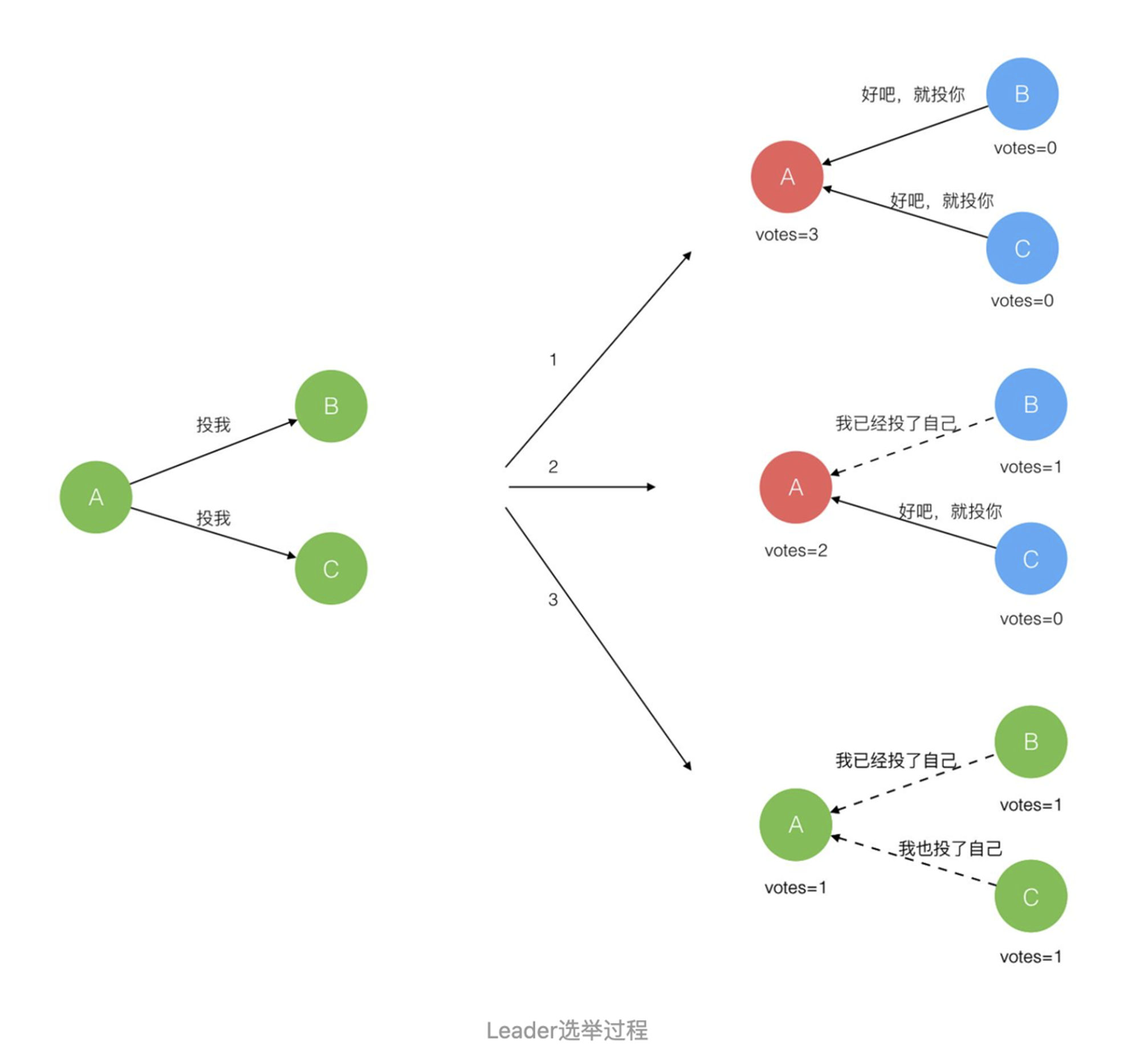
刚开始大家都是follower,是收不到heartbeat的
-
如果heartbeat timeout 超时,则开始发起新一轮选举
-
超过一半的选票则成为leader,自己也可以投票
-
Leader的选举 ------
-
Raft 使用心跳(heartbeat)触发Leader选举。
- 当服务器启动时,初始化为Follower。Leader向所有Followers周期性发送heartbeat。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。
- 选举出Leader后,Leader通过定期向所有Followers发送心跳信息维持其统治。若Follower一段时间未收到Leader的心跳则认为Leader可能已经挂了,再次发起Leader选举过程。
-
多数竞选,平票怎么处理,随机一个timeout时间,谁随机的时间短,下一次将会被选中
-
-
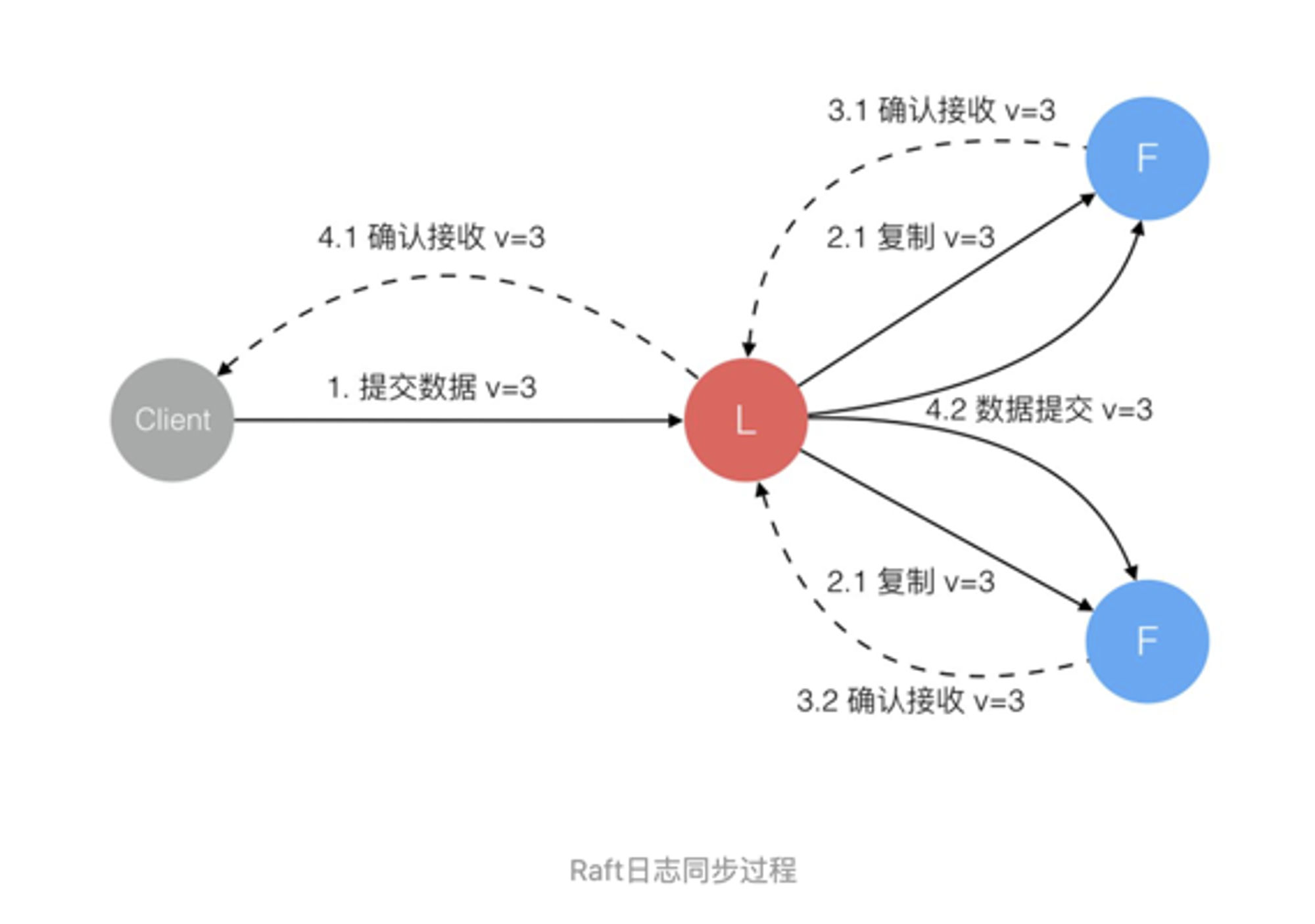
日志同步(Log replication),日志状态的同步
- 日志复制------
- 所有的请求都必须经过leader
- leader收到操作。将操作变成日志,传送给每个节点。节点收到日志后回复,大部分确认收到后,主节点确认操作。将确认操作发送给各个节点。
- Leader选出后,就开始接收客户端的请求。Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起 AppendEntries RPC (RPC细节参见八、Raft算法总结)复制日志条目。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。
-
安全性(Safety):保证共识是一致的
- 保持连接 ------
- leader通过心跳来和follower保持连接
- leader不断给节点发送心跳
- 用心跳heartbeat来确认主从之间的连接
- follower接收到心跳后,重置heartbeat timeout时间
- 心跳超时 heartbeat timeout,则触发重新选举
- 选举超时
- 心跳包还包括数据
- 日志压缩(Log compaction)、成员变更(Membership change)
- partition:出现分区
- 分区出现时:分区中选出leader
- 分区恢复后:leader是第几任,最新的一任为准
-
-
ZAB算法基本和raft相同。
- raft是leader向follower发送心跳。
- zab是follower向leader发送心跳。